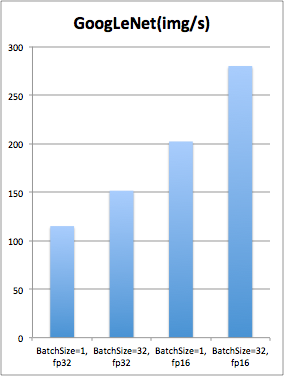
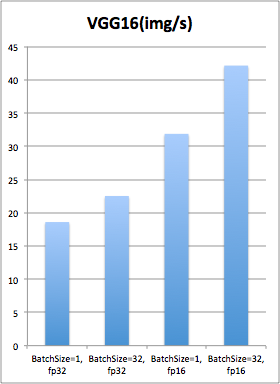
Jetson Xavier、Jetson TX2、 1080(Ti)、2080显卡运行深度学习模型性能对比
2020-11-12 16:43:47
英伟达的Jetson TX2使得很多人认为a深度学习模型终于可以像嵌入式开发平台那样做到小型化了,不用再跑在高配计算机或者服务器上面了,但是实际上Jetson TX2开发板的性能和深度学习常用到的1080(Ti)以及2080 还有一定的差距,接下来英伟达又出了一个Jetson Xavier,可以说是Jetson TX2的升级版,性能自然是强了很多,并且个人很喜欢的是英伟达把他封装成了一个小黑盒子,非常便携。
1、常见的GPU:RTX 2080 Ti、RTX 2080、GTX 1080 Ti、Titan V和Tesla V100
| 模型/GPU | 2080 | 2080 Ti | Titan V | V100 | 1080 Ti |
|---|---|---|---|---|---|
| RESNET-50 | 209.89 | 286.05 | 298.28 | 368.63 | 203.99 |
| RESNET-152 | 82.78 | 110.24 | 110.13 | 131.69 | 82.83 |
| InceptionV3 | 141.9 | 189.31 | 204.35 | 242.7 | 130.2 |
| InceptionV4 | 61.6 | 81 | 78.64 | 90.6 | 56.98 |
| VGG16 | 123.01 | 169.28 | 190.38 | 233 | 133.16 |
| AlexNet | 2567.38 | 3550.11 | 3729.64 | 4707.67 | 2720.59 |
| SSD300 | 111.04 | 148.51 | 153.55 | 186.8 | 107.71 |